Memory Alignment in 2021
16 May 2021I recently saw a small argument on the internet (shocking, I know) about whether it is important to care about memory alignment on modern computing hardware. One party claimed that alignment is not something you need to worry about in 2021 and that code which works to ensure it is correct is just getting in the way. The other party was arguing that such code is an important part of ensuring your program’s correctness.
Now I certainly cannot claim to be an expert on the matter. Memory alignment is something that I know exists, that I am led to believe has an impact on performance and/or correctness and that I have not really fiddled with myself at all. It is also something that seems fairly easy to investigate (at least at a high level).
The Test
To find out how much of a concern this is, we need some computationally-intensive task that we can do while referencing a bunch of heap memory. We can then modify our allocator to offset each allocation by some amount and run the task again to see if there is any behavioural difference.
For ages I’ve been meaning to look into Peter Shirley’s Raytracing in One Weekend series. Raytracing is a well-contained, interesting and computationally intensive task so I figured I’d go with that (and learn a little about raytracing along the way). I implemented the simple raytracer, keeping as much state on the heap as I could and then overloaded operator new() to get the alignment-fiddling (I just shifted everything up by 1 byte).
For a little variety I also added in two additional (much simpler) tests:
- Generate a bunch of random numbers, store them in a
std::vector, then read them out again to square them and sum the differences between the square of the current number and that of the previous one in the sequence. - Generate a bunch of random 3D vectors, store them in
std::vector, then read compute the dot product of each vector with the previous one in the sequence, store those in a new vector, and then sum that second vector.
Are these good tests for memory alignment? I have no clue, but they all involve reading reading, writing and doing some amount of arithmetic on a bunch of memory.
I ran the tests 6 times to get a not-entirely-useless sample. They were all be run on my desktop machine (which has an Intel Core i7-8700K CPU) and were compiled using the Visual Studio compiler version 19.13.
The Results
It would appear that those in the “this doesn’t matter at all” boat are right…at least for the most part and on modern x86 CPUs. Here are some graphs of how long it took to complete each task:
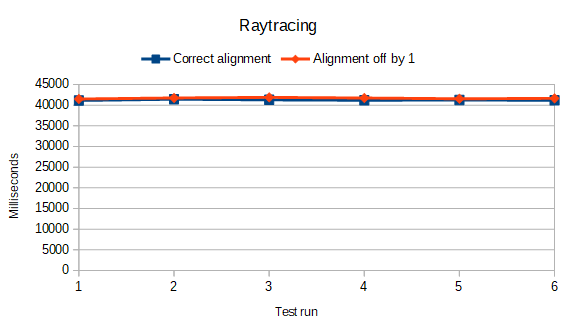
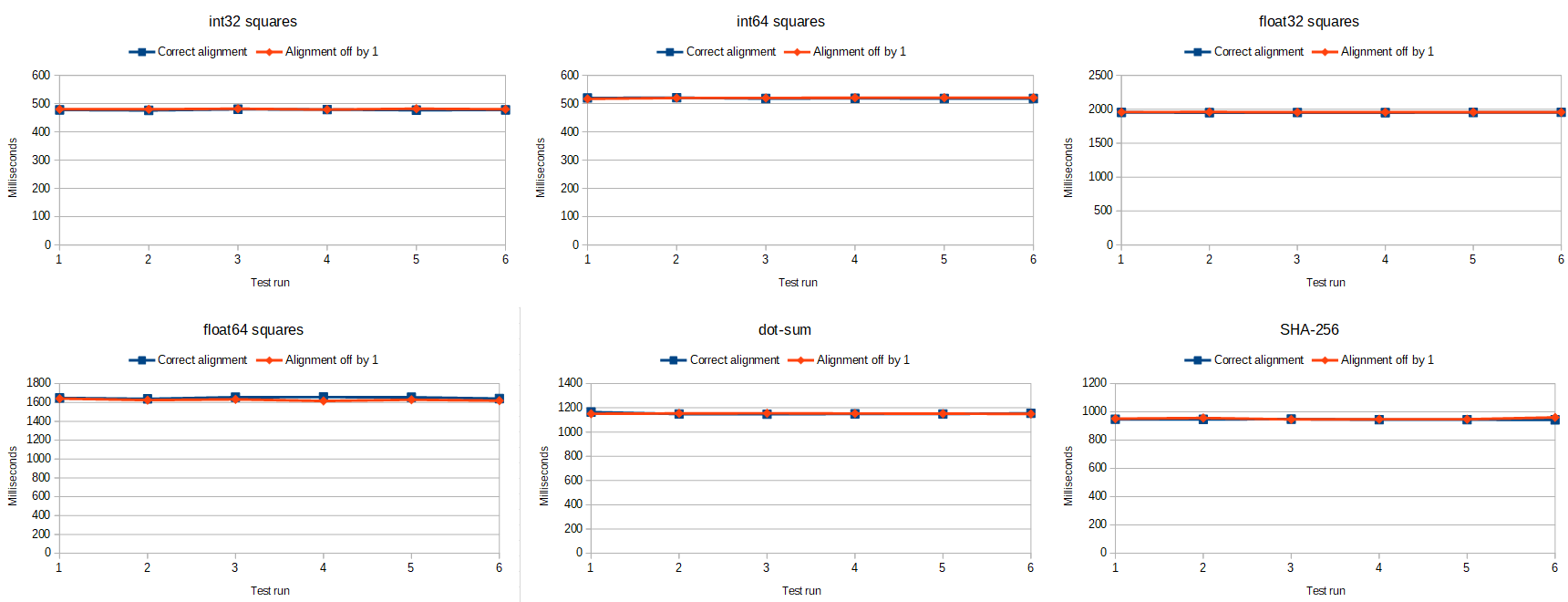
As you can see there is very little difference between the properly-aligned times and the not-aligned times! Good job Intel!
There is one caveat though. While most instructions work just fine on unaligned data (or at least appear to), some instructions will actually fail. At one point I changed my vec3 type to be a union of either 4 floats or an __m128 so that I could try write my own SIMD dot product for a comparison. After that, running the raytracer while the memory alignment had been changed resulted in a crash on a movaps instruction.
If you (like me) cannot quite read x86 assembly without a manual, you can consult some documentation and see that movaps stands for Move aligned & packed single-precision floating point values and that:
“When the source or destination operand is a memory operand, the operand must be aligned on a 16-byte […] boundary or a general-protection exception will be generated.”
Indeed if we look at the source operand of this failure, it points to a location in memory. Inspecting that location in memory reveals that it is a vec3 representing a colour, stored as part of a material that we allocated on the heap (and therefore intentionally mis-aligned) on startup. Bingo. This instruction was generated to copy the contents on one 3D-vector into another. So at least if you’re going to be writing SIMD code directly, you should probably check that your memory is properly aligned.
Similarly, the docs for the Windows InterlockedCompareExchange function specify that:
“The parameters for this function must be aligned on a 32-bit boundary; otherwise, the function will behave unpredictably on multiprocessor x86 systems and any non-x86 systems.”
I did a quick test for that and it didn’t crash but of course as with all things multithreading-related, I expect it depends on the relative timing of various operations (possibly resulting in things like torn reads/writes).
