Sounding smooth with jitter buffers
15 Jan 2018When discussing network connection quality, terms such as latency (or ping) and bandwidth are thrown around like its nobody’s business. They do not tell the whole story however (as I discovered while working on my experimental video-conferencing program, Veek), and miss out on one property that is crucial for real-time data transmission: Jitter.
Jitter and its effects
As you may know, latency is the time that it takes for a single packet to travel from one client to the other1. Jitter on the other hand, is a measure of how much that latency changes when many packets are sent over time. If you had two clients Alice and Bob, where Alice is sending packets to Bob at some constant rate (every 100 milliseconds, for example), then with no jitter Bob would always see a new packet arriving every 100ms (regardless of his latency to Alice).
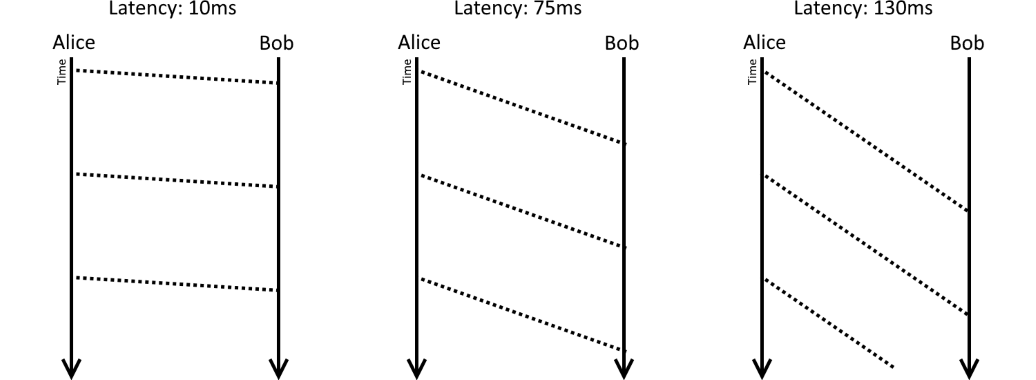
In the presence of jitter the packets that Alice is sending every 100ms might arrive only 80ms apart, or 110ms!
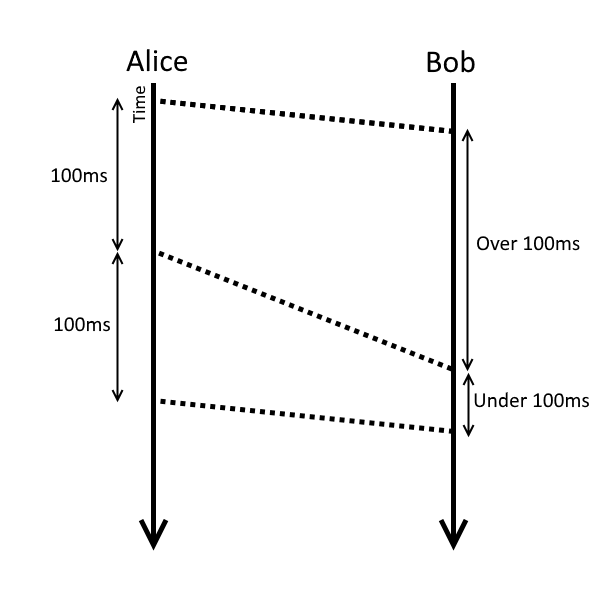
Jitter causes problems when you’re streaming information that is getting used in real time over a network. This is because the packets we’re sending every 100ms could contain exactly the right amount of data to keep us busy for 100ms, so if a packet arrives 15ms late then Bob will have to sit and twiddle his thumbs for 15ms while he waits for the extra packet. Not only that but Bob will now be 15ms behind where he expected to be, and so if he receives the next packet on time (which would be 85ms later), he won’t be ready to process it immediately.
Example problem case: Real-time audio streaming
Let’s say you need to send audio over a network in real time for some interactive application (maybe you’re implementing a VoIP solution or a video conferencing client (like Skype or Veek). The packets that you’re sending are simply the audio that Alice recorded from her microphone, being sent over to Bob so that he can play it back.
If Bob took the audio data from the packet and played it back immediately then any jitter at all would have an obvious negative impact on the quality of the audio signal that he hears. Any packets arriving early would cause a skip, where some piece of audio that was still playing from the previous packet gets overwritten by the new packet. Similarly any packets arriving late would cause a gap and Bob would hear nonsense2 until the next packet arrived and the audio continued its regularly scheduled programming.
Buffers (of the Jitter variety) to the rescue!
In a nutshell a jitter buffer is essentially a (relatively small) buffer that you introduce between the receipt of audio data from the network and sending it to the audio output device for playback.
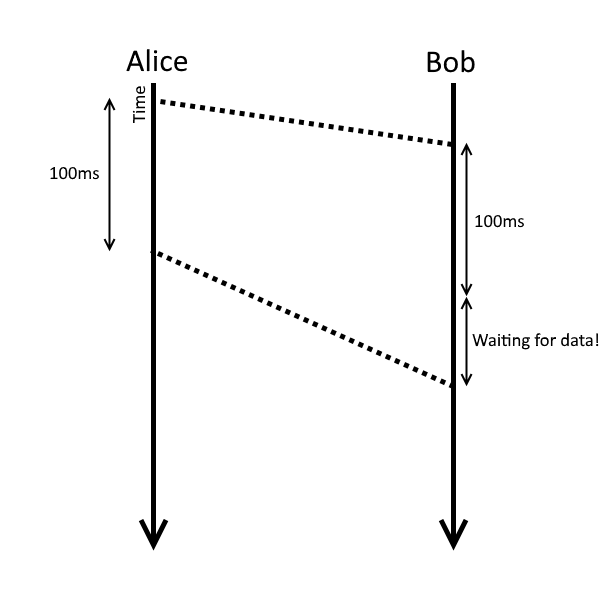
You could create a simple jitter buffer with just a queue of some fixed length. This introduces a small amount of latency to all of your audio playback (since the data spends time sitting in the buffer, on top of the time it takes to traverse the network, audio driver etc), but that by itself gives some protection against jitter. It’s easy to see why this is true if we consider a case where Alice is sending packets every 100ms and each packet could take up to 20ms more (or less) time to get there. Even a buffer of a single packet would ensure that we never try to send data to the audio driver and don’t have any, or that any audio gets overwritten by a new packet arriving.
This simple buffer will fail pretty quickly if the amount of jitter approaches the time between packets:
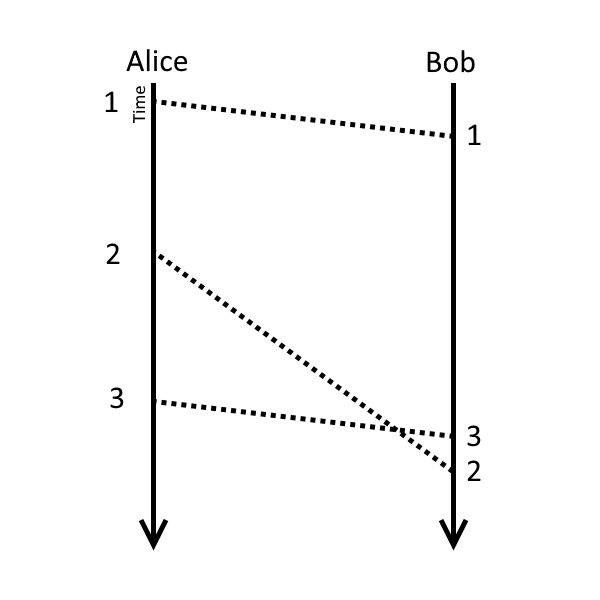
To solve this we need some extra intelligence in our buffer but we also need to know what the correct ordering of the audio data is. This is achieved by having Alice tag every audio packet with a timestamp to indicate where in the audio stream that packet resides. When the packet is received and the data inserted into our buffer, we insert it with the timestamp. This lets the buffer re-order the packets internally as needed to ensure that packets get played back in the order in which they were recorded.
Note that there are at least two ways of timestamping packets: You could just use the index of the whole packet or you could use the first sample and a length. In the case of Veek, all the audio packets contain the same length of audio so I just index the packets (IE first packet is 0, then 1, then 2 etc), which means that you can only pull out whole packets as they were inserted but that’s fine. There is, however, a jitter buffer implementation in libspeexdsp that takes the approach of giving a timestamp and length with each packet, and then allowing you to ask for data with an arbitrary timestamp.
How large should the buffer be?
That is an excellent question and as with many excellent questions, the answer is “it depends”. On one hand you want it to be large enough to store a duration of audio which exceeds the jitter of the network connection. On the other hand a large jitter buffer means a higher effective latency for the audio signal (because the data spends time sitting in the buffer).
Today the cool kids all use adaptive jitter buffers. These grow and shrink in size over time in an attempt to keep the jitter buffer as small as possible while still being large enough to prevent jitter from being a problem. The details of how this works are beyond the scope of this article but a simple way to calculate jitter on-the-fly is explained here and for reference the implementation included in libspeexdsp is an adaptive jitter buffer.
The alternative (possibly unsurprisingly) is called a “Fixed Jitter Buffer”, which has a (gasp) fixed size. In this case you would obviously need to set a size ahead of time and what that size is depends on your application. If you’re expecting low jitter (for example if you’re only working on a local network or one that is controlled and of high quality) then your buffer can be smaller, otherwise (lets say you want to send packets over the internet to the other side of the world) you’ll need a larger buffer. I can’t tell you what a good size might be but the ITU recommends that total one-way delay from recording to playback is less than 400 milliseconds (with under 150ms being considered good). In Veek I set the jitter buffer to 60ms3, in part because I wanted it to store whole packets and my packets are each 20ms of audio.
Regardless of how you set the size of the buffer, any buffer that has finite size needs to decide what to do both when it is empty and when it is full. The empty case is pretty simple: we don’t have any data so we output nothing and let the application handle that as it would any other packet loss4. When the buffer is full you have more options but ultimately you either need to have a scheme for growing the buffer (which increases the latency that the buffer is responsible for) or you need to drop some packets.
Conclusion
So there you have it. An overview of what a jitter buffer is, what problem it might help to solve, and some considerations when creating or using one. This post is far from being an in-depth reference on jitter buffers but I struggled to find clear explanations about them when I was trying to create one myself so hopefully you’ve stumbled on this page while researching and learned something!
…and back again, depending on who you ask. The point is that it’s a measure of how long it takes for data to get from one machine to the other. ↩︎
Exactly what nonsense gets heard depends on the details of how the audio playback works but without some form of intervention it would most likely be something that was played recently and is still sitting in memory. ↩︎
Sort of, I gave it a full capacity of 120ms and had it try to stay half full (to allow maximum flexibility in both directions). A friend pointed out that there isn’t really a reason to set a maximum size (at least not a small one) but I have yet to try this out. ↩︎
In the case of audio this might not mean complete loss of the signal. Codecs such as xiph.org’s Opus have so-called “Packet Loss Concealment” that lets it output a lower-quality signal in the place of a lost packet, resulting in less noticeable artefacts than outputting silence or repeating old data. ↩︎