Implementing DNS: RFCs can be sneaky
28 Mar 2020We’ve all seen DNS at work. You probably used it to get to this site (if not then who are you and why do you know the IP for my site off-hand?). But how does it work? Sure there are high-level descriptions of it in most Computer Science courses the world over and certainly the internet has no shortage of hand-waving descriptions. When we get down to the finer details though, how does one really create a client that talks directly to a DNS server to get IP addresses from domain names?
I wrote a simple tool for making domain queries because I got fed up with trying to find and figure out dig on the fairly-rare occasion that I needed to just make a simple DNS query. In doing so I ran into 2 particular issues that took me a bit longer to resolve than I’d hope and that I didn’t see much info about on the internet so here they are for all of you:
Issue #1: Why are servers not handling my (seemingly very reasonable) requests at all
Apart from the aforementioned hand-waving, there isn’t a huge amount of explanation on the internet about how DNS works. I think this is actually a good thing because it suggests that actually it’s really simple and there’s a sufficiently-detailed RFC to tell you all about it.
So I look it up (I actually read the version here which is the same RFC just with better diagrams and split into pages), skim over it to find some diagrams and explanations of what packets look like, check the port I should be sending to, and off we go on implementing. Blast through that in a few minutes, send off a hard-coded request, check the result in wireshark…and its not returning the response that we expect.
Of course not, nothing works the first time. No matter, lets compare our request to one sent by dig:


See the difference? I sure didn’t the first time…nor the tenth time. A quick rant to a friend about how technology doesn’t make sense and I come back to wireshark and flip back and forth between the successful request sent by dig and the failed request sent by me. This manages to highlight some differences. Let’s take a look at those packets again, this time with some annotations:


3 whole bytes! The first one is just the request ID, which doesn’t do anything other than let us connect requests to responses. The other two are the interesting ones: the first is the byte just before the start of the domain name string and the second is the byte where the dot would be between the ‘jacquesheunis’ and ‘com’.
So here we arrive at the lesson: If you’re going to read and implement an RFC, actually read it rather than just skimming it. To help you out I’ll quote the line from the RFC that describes what the name field contains in a query: “a domain name represented as a sequence of labels, where each label consists of a length octet followed by that number of octets. The domain name terminates with the zero length octet for the null label of the root.” However without thinking I’d equated “label” to “domain name” (and then seemingly ignored the whole “sequence” bit) when actually they mean “the part of a domain between the dots”. The RFC does technically tell you that a label can’t contain a dot and that a domain is a list of subdomains separated by dots, but its a little hidden in the specification of the grammar for names.
That’s that problem then, we update our serialization to include length bytes instead of dots and off we go again. It works beautifully, we send a request and wireshark shows us the successful response. Perfect. Next up is parsing that response in our program, which is where we run into:
Issue #2: How do I know which query an answer corresponds to?
We’re now making a request and receiving a response that clearly contains the correct bytes for the IP we’re looking for. This is good. The only problem is that according to the RFC, an answer record starts with a name field whose value is described only as “an owner name, i.e., the name of the node to which this resource record pertains”. This tells us nothing about the format so I initially assumed that it’d be a string just like in the question record. If we take a look at the contents of the response though, the answer record starts with the bytes 0xc00c and then goes right on to the remaining fields in the answer record. What on earth is 0xc00c?
Cue much confusion and internet-searching on my part. This is a case where the internet’s treasure-trove of vague descriptions of DNS really hurt. I struggled to find anybody asking or answering any questions about what the format of the resource name field.
Fast-forward through all the internet-searching and I eventually stumble upon the webpage for Prof. Fuligni’s computer networking course and in particular the DNS Primer. It contains an example DNS request and response, with the function of each byte explained. It describes 0xc as “Name is a pointer” and 0x00c as “Pointer is to the name at offset 0x00c”. Pointers…this is a new addition to the terms I’ve seen in the RFC, so I go back and look over it again, this time a bit more thoroughly. Sure enough, right there in the very next section we have “4.1.4: Message compression”.
Note that a response in the DNS protocol contains both the response data (e.g the IP for a given domain name) and the request data (the domain name to look up). The authors of the original RFC noticed that this results in the consistent inclusion of duplicate data: The domain name itself. In an effort to reduce size of DNS packets they defined labels as either a string literal or a pointer to another string literal already included elsewhere in the packet. A pointer is denoted by a length-byte where the highest two bits are both set. In that case the remaining 6 bits, along with the following byte, make up an offset into the UDP packet from which we should read the remainder of the label. In my case we have 0xc00c which in binary is 0b1100000000001100. The leading 0b11 tells us that we have a pointer and the trailing 0b00000000001100 specifies that we should start reading labels from the 12th byte of the packet. Unsurprisingly, the 12th byte is the length byte of the domain in our question section.
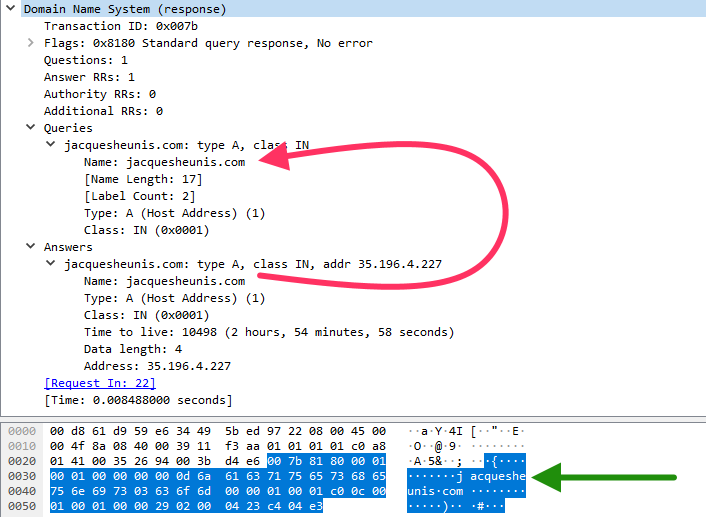
So we update our deserialisation function to understand and follow pointers and boom! We now have a functioning (albeit basic) DNS client implementation! In contrast to the first issue, I think the lesson here is that you should probably not just read the one tiny section of an RFC that you think relates to you. Read all of it (or at least most of it).
In fact by reading more documentation more often you might learn some interesting things! For example not only can a name field in a DNS response be a pointer, it can start out as a string literal for the first few labels and then a later label can be a pointer. This means we could theoretically send a request for ‘foo.bar.baz’ and get a response for ‘foo.bar.baz’ and ‘bonus.foo.bar.baz’ without any duplication of labels! The labels in the second response would be ‘bonus’ followed by ‘pointer to the domain in the request’.
A wild closing paragraph appears!
Well that’s all for today. This post maybe wasn’t quite as educational as one might hope but the RFC is available for all to read and I didn’t want to spend too long on this post to increase the chances that it actually got published. I hope I help at least a few people learn something or get their DNS implementation working a little faster.
If you want to see the code for my DNS implementation, you can find it here on github