Hidden friends with compile-time benefits
28 Aug 2021Recently I’ve been thinking about how I could reduce the compilation time of my C++ code (aren’t we all). I also recently saw some people discussing the so-called “hidden friend” idiom in C++ and its various benefits. One of the claimed benefits of hidden friends is that they simplify the compiler’s job, speeding up compilation. I thought I’d investigate.
What is a “hidden friend”?
A hidden friend is a free function (usually an operator overload) defined in a class definition as a friend. This function is then not found by normal symbol lookup but is found in the argument-dependent lookup that follows. This has several benefits ranging from avoiding implicit conversions to making it harder for minor typos to cause major changes in behaviour and speeding up compilation.
Does it really speed up compilation?
Short answer: Most definitely. At least on my contrived test example that I constructed specifically to check this.
Long answer: I threw together some python code that would generate some types and some equality operators between them. This lets us generate an arbitrarily large quantity of operator== overloads and see if switching between free functions to hidden friend functions has any impact on compile time. If you’re interested, the code I used can be downloaded here.
As an example, the code generated for the free-function variant looks like this:
struct T0 {
int data;
};
bool operator==(const T0& lhs, const T0& rhs) { return lhs.data == rhs.data; }
while the code generated for the hidden-friend variant looks like this:
struct T0 {
int data;
friend bool operator==(const T0& lhs, const T0& rhs) { return lhs.data == rhs.data; }
};
Timing compilation of that code produces some pretty clear results:
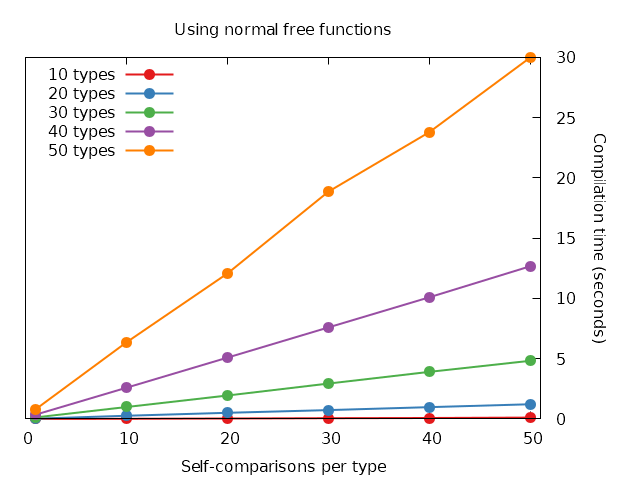
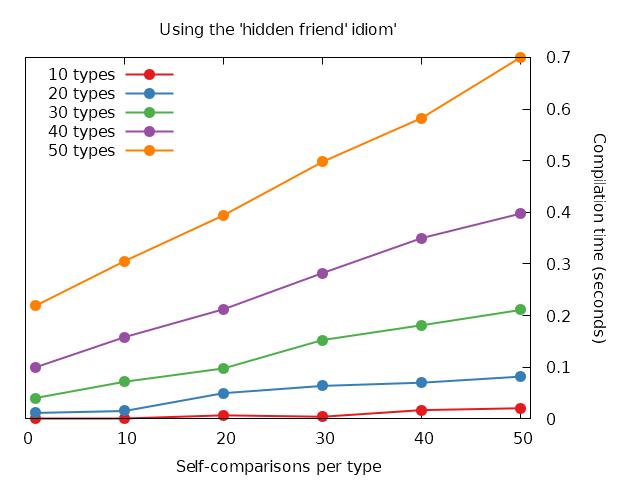
With 50 types and each one calling operator== 50 times, it takes roughly 23 times longer to compile the free-function version. That’s quite a difference! Just for clarity, lets take a look at that one more time with the two large instances side-by-side:
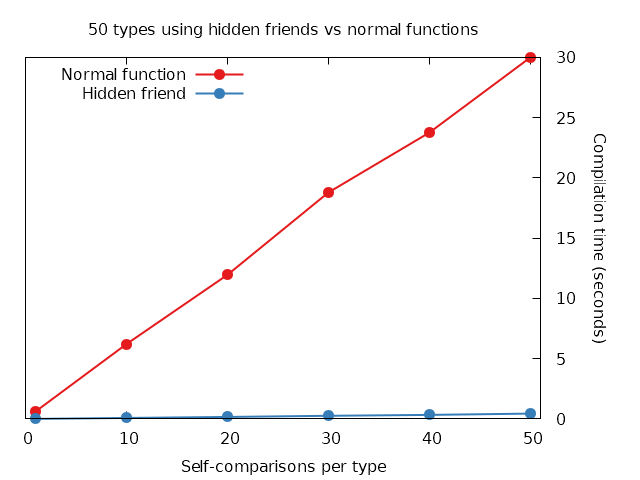
Where does all that time go?!
Overload resolution! I believe the difference is that the set of overloads that it needs to pick through is much smaller and it does less work for each one (because ADL doesn’t try to find conversions for the arguments, they need to match exactly). This belief is backed up by the fact that if you define the function at block scope and in the type declaration you just mark it as a friend then it takes the same amount of time as if you hadn’t declared it a friend at all - so the inline declaration is important! This also lines up with the ADL docs which specify that ADL is ignored if the symbol is found at block scope (whereas when we do the hidden-friend thing we’re defining it at class scope).
What’s next?
Contrived test examples always need to come well-seasoned. If somebody wants to try this out on a large real-world codebase I would be very interested in what the results are! Also worth noting is that I didn’t use any templates, which are always a source of compile-time fun. Since templates would generate additional overloads to resolve, I expect it would be roughly equivalent to just having more types in the namespace with operator== defined.